Imperative Deployment vs. Declarative Desired State
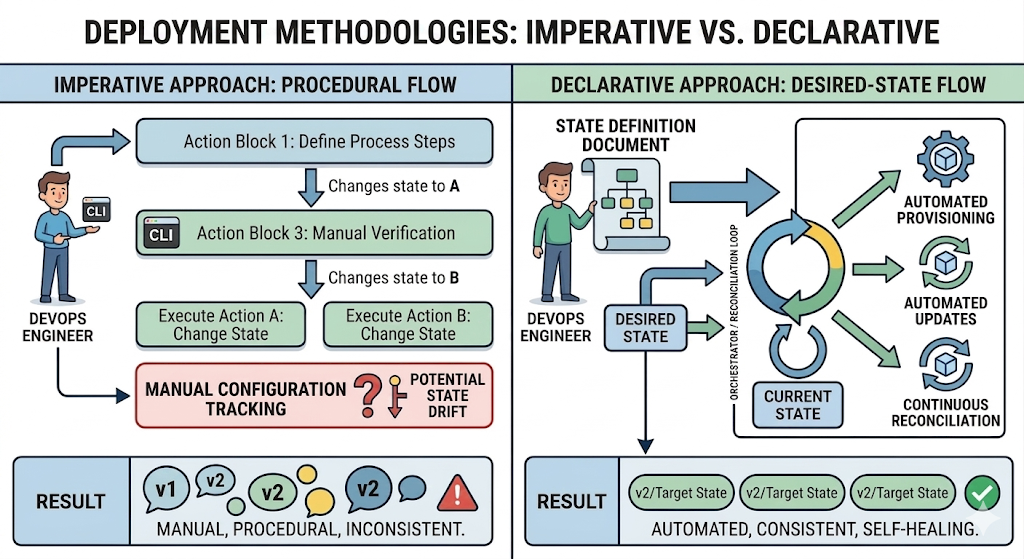
Imperative (Procedural Flow): Focuses on the manual execution of a specific sequence of commands, requiring the operator to manage state transitions directly, which increases complexity and the risk of configuration drift.
Declarative (Desired-State Flow): Uses an automated orchestrator (a reconciliation loop) that continuously compares the actual system state with a predefined state definition document. It handles provisioning and updates automatically to ensure consistent, self-healing environments.
In a very simple ecosystem, an imperative approach to deployments can be effective. For each target environment, the component promotion (the staging from Test to Production for example) can be timed by the DevOps engineer to ensure the combination of components that were tested are consistent with those that go live.
Drift, When things go wrong…
In this example, due to an oversight, the user interface was promoted to Production without the correct API version. The user interface fails in production even though it worked in test as expected, and a critical dependent API operation is now not available due to a drift.
Backend
Frontend
To add more complications, there is another version of the user interface in test now. What version of the API does it require?
This approach is not scalable, where an ecosystem has many components, and many environments, the complexity grows exponentially and the chances of manual errors leading to inconsistency increase.
There are two distinct and important concepts to cover, Declarative & Desired State.
Declarative
Declarative is a style of implementation where you describe what you want to achieve, rather than how to achieve it. In a declarative approach, you specify the desired outcome or state of the system, and the underlying implementation takes care of the details.
Desired State
Desired State refers to the specific configuration or condition that you want a system to be in. It represents the target state that you want to achieve, and it is often used in the context of infrastructure management, configuration management, and orchestration.
Orchestrated Deployment
Orchestrated Deployment is a process of managing and automating the deployment of applications and services in a way that ensures they are deployed in the desired state. It involves coordinating various components and resources to achieve the desired outcome, often using tools and frameworks that support declarative configurations.
In an orchestrated deployment, you would typically define the desired state of your application, such as the number of replicas, resource requirements, and network configurations. The orchestration tool would then take care of deploying the application according to the specified desired state, ensuring that it is running and functioning as intended.
In summary, a declarative approach focuses on describing the desired state of the system, while an orchestrated deployment is a method of achieving that desired state through automation and coordination of resources.
What does it actually look like?
There are a variety of declarative notations:
For virtual machine machines there are Chef, Salt, Puppet, Ansible, etc. and for Windows Desired State Configuration (DSC) or Active Directory Group Policies.
For containers there are Kubernetes, Docker Compose, and HashiCorp Nomad. For serverless there are AWS CloudFormation, Azure Resource Manager, and Google Cloud Deployment Manager.
For public cloud infrastructure and a broad range open-source and commercial production, Terraform has become the pseudo-standard.
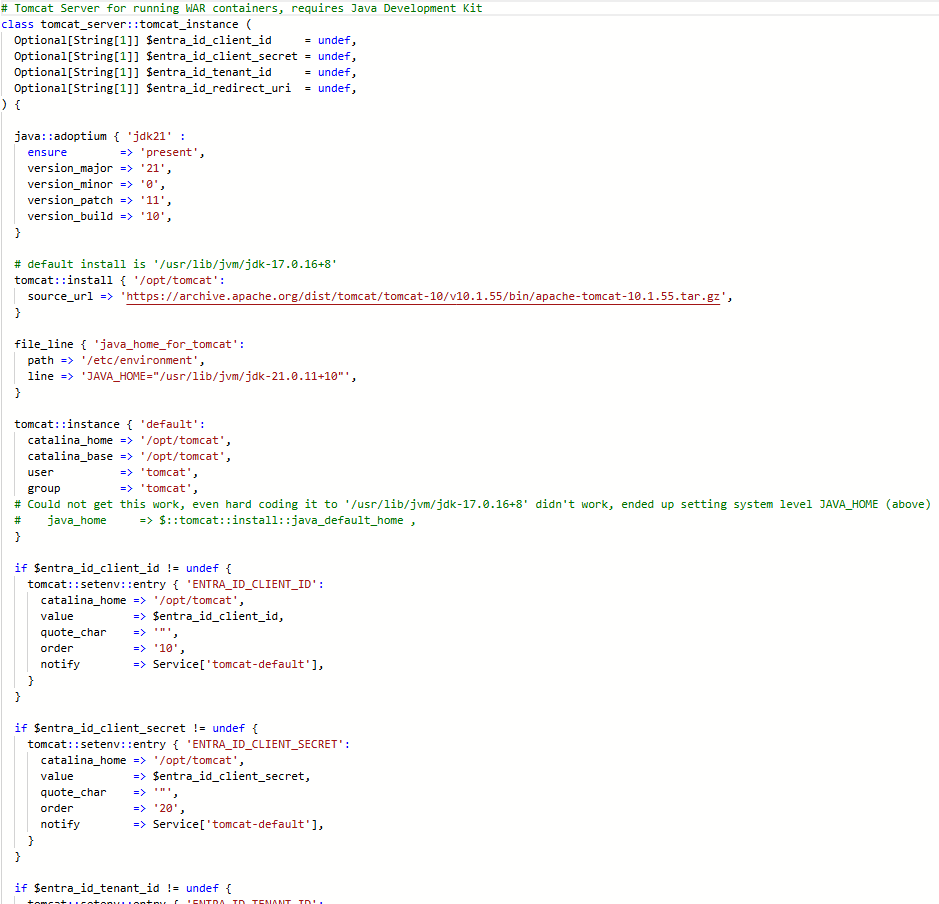
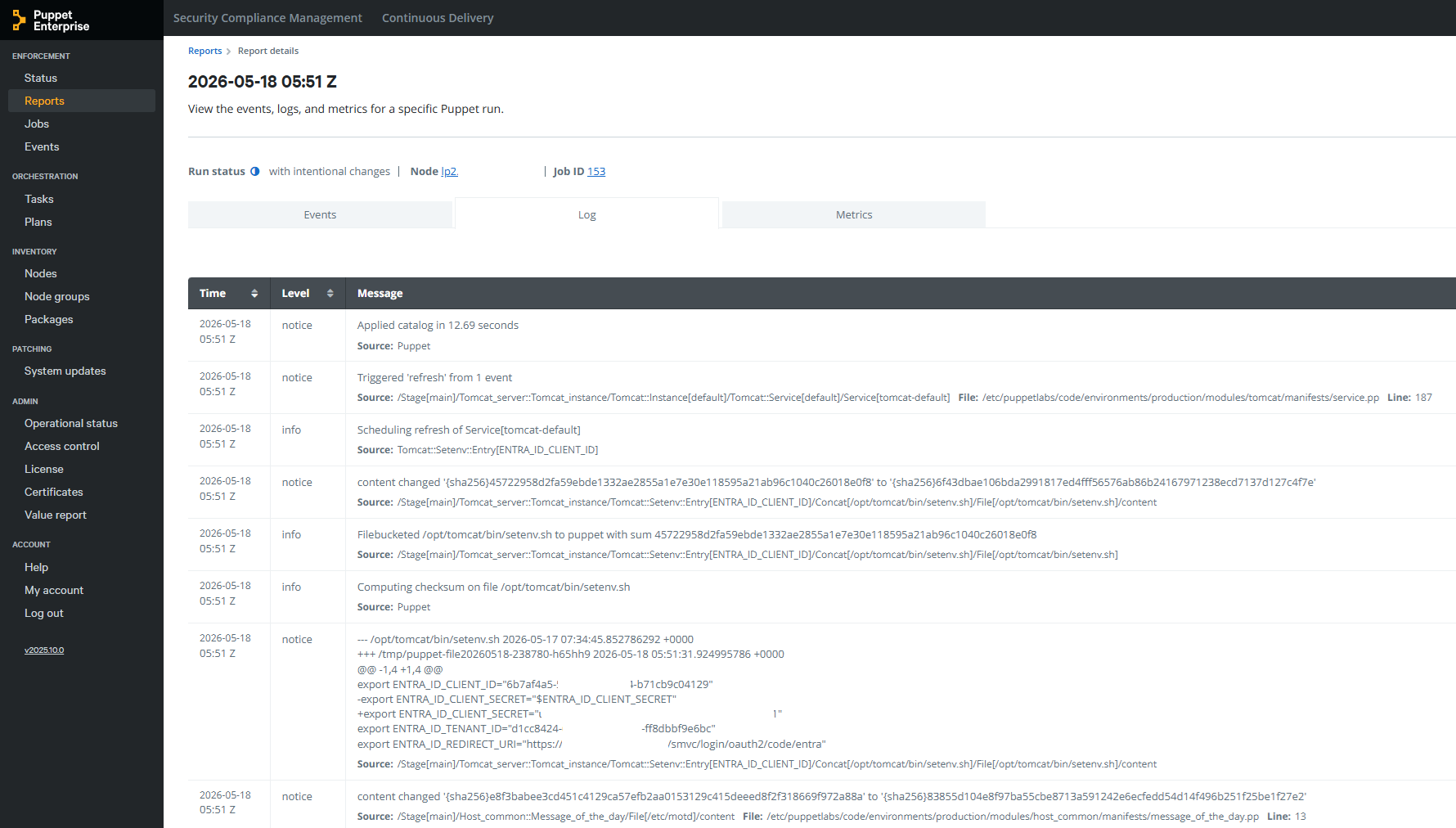
This example is Puppet applying environment variables to a Tomcat server.
Declaration
Application of Desired State
Implementation Patterns with CDAF Declarative Release for implementation examples, which incorporate intermediary tools such Ansible Tower, Puppet Enterprise and Terraform Cloud
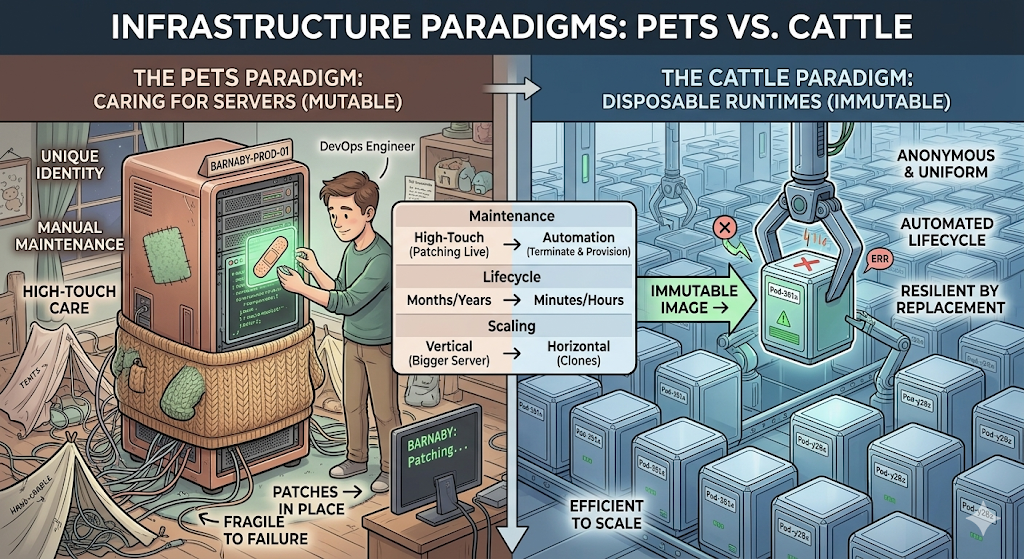
In a traditional infrastructure model, servers are treated like domesticated pets. They are given unique names, carefully nurtured, and kept alive at all costs.
Individual Identification: Every server has a distinct identity (e.g., prod-oracle-db-02 or billing-app-srv). Engineers know exactly what runs on which machine.
Mutable State: Software updates, security patches, and configuration tweaks are applied directly to the live, running server over time.
High-Touch Maintenance: When a server acts up, an engineer logs in via SSH to diagnose the issue, read local logs, and manually repair it.
The Cost of Failure: Because the server is unique, its downtime is an operational emergency. If it dies, rebuilding it exactly as it was can take hours or days, often leading to data loss or “configuration drift” (where no one is entirely sure how the server was originally configured).
Disposable Runtimes (The “Cattle” Paradigm)
In modern cloud-native architectures, infrastructure is treated like cattle or disposable machinery. Runtimes—such as Docker containers, micro-VMs, or serverless functions—are completely anonymous, identical, and easily replaced.
Anonymity & Uniformity: Runtimes do not have individual names; they have auto-generated IDs (e.g., srv-pod-x89f2). Every instance in a cluster is a perfect clone of the other.
Immutable Infrastructure: You never modify a running container or runtime. If you need to update an application or patch an OS vulnerability, you build a new container image and swap the old ones out.
Automated Lifecycle: Runtimes are designed to be ephemeral. They are spun up when traffic spikes and instantly torn down when demand drops. They might live for only a few minutes or hours.
The Cost of Failure: Disposability transforms failure into a non-event. If a container exhibits an error, becomes unresponsive, or runs out of memory, the orchestrator (like Kubernetes) immediately terminates it and provisions a brand-new, healthy replica in seconds.